
1 Introduction
この文章は、マルチモーダル(MM)事前学習という分野での最近の研究進展についての概要を説明しています。特に、マルチモーダル・ラージ言語モデル(MM-LLM)に焦点を当てています。以下、主要なポイントを解説します。
- マルチモーダル事前学習の進展: MM-LLMの研究は近年顕著な進歩を遂げており、様々なダウンストリームタスクにおいて性能の境界を押し上げています。しかし、モデルとデータセットの規模が増大するにつれて、従来のMMモデルでは、特にスクラッチからのトレーニング時に膨大な計算コストがかかるようになりました。
- LLMの利用: MM研究は様々なモダリティの交差点で展開されていますが、計算コストを抑え、MM事前学習の効率を向上させるために、既存の強力な大規模言語モデル(LLM)を活用するアプローチが提案されています。これにより、新しい分野としてMM-LLMが出現しました。
- MM-LLMの特徴: MM-LLMは、LLMを知的な中核として利用し、強力な言語生成能力、ゼロショット転移能力、文脈内学習(ICL)などの特性を提供します。同時に、他のモダリティの基礎モデルは高品質な表現を提供します。主な課題は、LLMを他のモダリティのモデルと効果的に結びつけ、共同で推論を可能にする方法を見つけることです。この分野では、モダリティ間の整合性を高め、人間の意図に沿った整合性を確保することに重点を置いています。
- 最近の進展とトレンド: GPT-4(Vision)やGeminiなどの登場により、MM-LLMに対する研究熱が高まっています。初期の研究は主にMMコンテンツの理解とテキスト生成に焦点を当てていましたが、最近では、画像生成や音声生成など、特定のモダリティの生成に関する研究も増えています。更に、人間のような任意のモダリティ間変換を模倣する研究や、外部ツールとLLMを統合する試みも行われています。
- 本論文の概要: 本論文では、MM-LLMのさらなる研究を促進するための包括的な調査を提供します。モデルのアーキテクチャ、トレーニングパイプライン、主要なデータセット、最先端のMM-LLMの特徴やトレンド、主要なベンチマークでの性能評価、研究の有望な方向性などについて、詳細な説明が行われます。また、MM-LLMの最新の進展を追跡し、コミュニティによる更新を促進するためのウェブサイトも設立されています。
2 Model Architecture
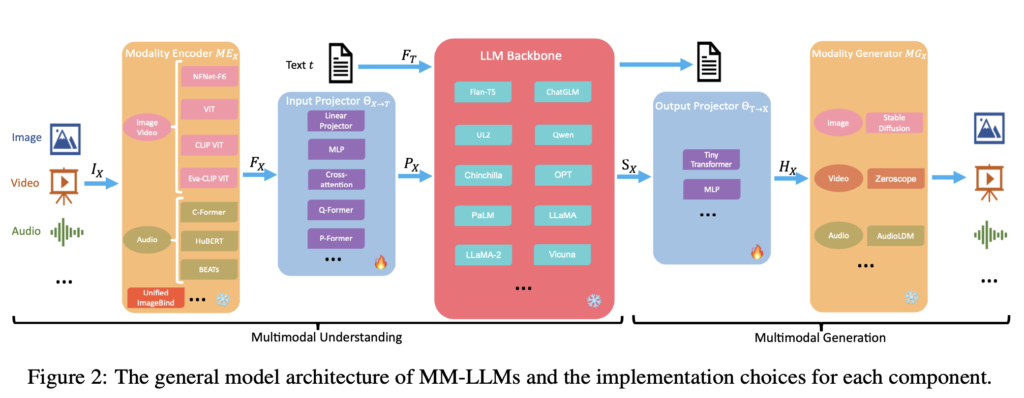
この節では、マルチモーダル・ラージ言語モデル(MM-LLM)の一般的なモデルアーキテクチャを構成する五つの主要コンポーネントについて詳細な概観を提供しています。それぞれのコンポーネントに対する実装選択も含まれており、MM-LLMの理解を深めるために重要です。以下、各コンポーネントについて要点をまとめます。
2.1 モダリティエンコーダ (Modality Encoder)
このコンポーネントは、異なるモダリティ(画像、ビデオ、オーディオなど)からの入力を受け取り、それらを特徴ベクトルにエンコードします。具体的には、画像にはNFNet-F6やViTなどのエンコーダ、オーディオにはC-FormerやHuBERTなど、3DポイントクラウドにはULIP-2などが使用されます。また、複数のモダリティを統合的に扱うために、ImageBindなどの統一エンコーダも紹介されています。
2.2 入力プロジェクター (Input Projector)
入力プロジェクターは、モダリティエンコーダによって得られた特徴ベクトルを、テキスト特徴空間に整列させる役割を果たします。具体的には、エンコードされた特徴をLLMバックボーンに適した形に変換し、テキスト生成のための最適化を行います。実装方法としては、線形プロジェクターや多層パーセプトロン(MLP)があります。より複雑な実装としては、クロスアテンションやQ-Former、P-Formerなどが紹介されています。
2.3 LLMバックボーン (LLM Backbone)
LLMバックボーンは、エンコードされた様々なモダリティの情報を処理し、意味理解や推論、決定を行うコアコンポーネントです。ゼロショット一般化や、少数ショットの文脈内学習(ICL)、チェーンオブソート(CoT)、命令に従うといった能力を有しています。また、パラメータ効率の良い微調整手法として、プレフィックスチューニングやアダプター、LoRAなどが紹介されています。
2.4 出力プロジェクター (Output Projector)
出力プロジェクターは、LLMバックボーンから得られるシグナルトークンを、次に続くモダリティジェネレーターが理解できる特徴にマッピングする役割を持っています。最適化はキャプションテキストに依存し、実際のオーディオやビジュアルリソースを使用しないことが特徴です。実装方法としては、小さなトランスフォーマーやMLPが使用されます。
2.5 モダリティジェネレーター (Modality Generator)
モダリティジェネレーターは、出力プロジェクターによってマップされた特徴を条件として、異なるモダリティのコンテンツを生成するタスクを担います。画像合成には安定した拡散モデル(Stable Diffusion)、ビデオ合成にはZeroscope、オーディオ合成にはAudioLDM-2などが使用されます。
この節では、MM-LLMの構造を構成する各コンポーネントの機能と役割について詳細に説明しています。これらのコンポーネントは、異なるモダリティの情報を統合し、それらを理解・生成する能力を持つMM-LLMの根幹を形成しています。AIの専門家にとって、これらの詳細は、MM-LLMの内部動作の理解を深め、今後の研究や応用への洞察を提供するものです。
3 Training Pipeline
マルチモーダル・ラージ言語モデル(MM-LLM)のトレーニングプロセスは、主に二つの段階、事前トレーニング(MM PT)とインストラクションチューニング(MM IT)に分かれます。
MM PT(事前トレーニング)
この段階では、異なるモダリティ(画像、ビデオ、オーディオなど)のデータを扱う能力をモデルに学習させます。具体的には、モデルの入力プロジェクターと出力プロジェクターが、様々なモダリティ間で整合性を持つように最適化されます。この最適化は、特にモダリティの理解が必要なモデルや、モダリティの生成を行うモデルで重要です。
MM IT(インストラクションチューニング)
こちらは、事前にトレーニングされたMM-LLMを、さらに指示に基づいて微調整する段階です。このプロセスを通じて、モデルは新しい指示を理解し、未確認のタスクにも対応できるようになります。この段階では、特に二つの方法が用いられます:監視下での微調整(SFT)と、人間のフィードバックからの強化学習(RLHF)。SFTでは、事前トレーニングデータを指示に従って最適化します。一方、RLHFでは、人間からのフィードバック(例えば自然言語のフィードバック)を用いて、モデルの応答能力をより洗練させます。
要するに、MM-LLMのトレーニングは、様々なモダリティのデータを効果的に理解し生成する能力をモデルに学習させるための複数の段階を含んでいます。また、新しい指示に基づいてタスクを一般化し、人間とのやり取りを自然かつ効果的に行う能力を高めるために、微調整のプロセスが重要な役割を果たしています。
4 SOTA MM-LLMs

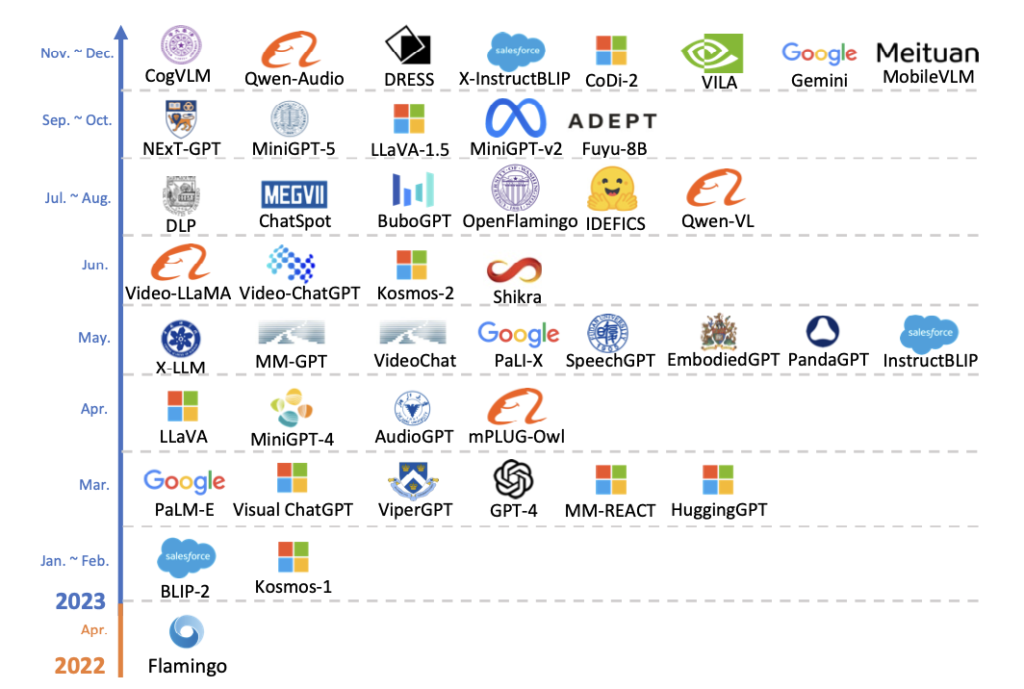
この章では、現在の最先端を代表する26のマルチモーダル・ラージ言語モデル(MM-LLM)について、そのアーキテクチャやトレーニングデータセット、主要な貢献と開発傾向を要約しています。これらのモデルは、様々なモダリティ(視覚、音声、テキストなど)を統合し、理解や生成などのタスクを実行できるよう設計されています。
主要なモデルとその貢献:
- Flamingo, BLIP-2, LLaVA, MiniGPT-4などは、視覚言語モデルの進化を示し、視覚データとテキストを連携させ、自由形式のテキスト出力や画像からテキストへのゼロショット生成を可能にします。
- mPLUG-Owl, X-LLMなどは、視覚コンテキストを組み込み、オーディオなどの様々なモダリティに拡張し、多言語サポートやモダリティのスケーラビリティを強化しています。
- VideoChat, Video-LLaMA, Video-ChatGPTなどは、ビデオ理解やビデオ会話に特化し、視覚と言語、オーディオと言語の整合性を高めています。
- InstructBLIP, PandaGPT, PaLIXなどは、多様なモダリティ間での指示に基づく操作の理解と実行を目指し、特定のモダリティ生成から任意のモダリティ変換への進化を示しています。
開発傾向:
- モダリティ理解から特定モダリティ生成への進化: 初期のモデルはモダリティ理解に重点を置いていましたが、最近のモデルは特定のモダリティの生成から任意のモダリティへの変換能力を有しています。
- トレーニングパイプラインの進化: 事前トレーニングから監視下での微調整、さらには人間のフィードバックからの強化学習へと進化し、人間の意図との整合性やモデルの対話能力を高めています。
- 多様なモダリティ拡張への取り組み: 初期のモデルは特定のモダリティに特化していましたが、最近のモデルは複数のモダリティを統合し、より包括的な理解と生成を目指しています。
- 高品質なトレーニングデータセットの採用: 効果的なトレーニングとモデルの性能向上のために、より質の高いトレーニングデータセットが採用されています。
- 効率的なモデルアーキテクチャへの移行: 複雑な入力プロジェクターモジュールからシンプルで効果的な線形プロジェクターへと、モデルアーキテクチャが進化しています。
以上のように、MM-LLMは急速に進化し、多様なモダリティを統合することで、よりリッチで自然な人間とのインタラクションを実現するための可能性を広げています。これらの進化は、AIの専門家にとって、モダリティの統合やAIシステムの対話能力の強化に関する新たな洞察を提供し、今後の研究や開発の方向性に影響を与えるものと期待されます。
