
マルチモーダル大規模言語モデル (MLLM) の評価
マルチモーダル大規模言語モデル(MLLM)の興隆に伴い、OpenAIのGPT-4VやGoogleのGeminiなどが注目されています。これらのモデルは、視覚理解能力を大規模言語モデル(LLM)に追加し、多様なマルチモーダルタスクへの適用を促進しています。しかし、Geminiが一般的な常識推論タスクでGPTモデルに劣るという初期のベンチマークがあり、これは限られたデータセット(HellaSWAG)に基づく評価であり、Geminiの真の常識推論能力を完全には捉えていません。本研究では、様々なモダリティにまたがる常識知識の統合を必要とする複雑な推論タスクにおけるGeminiのパフォーマンスを徹底的に評価します。結果として、Geminiは競争力のある常識推論能力を有していることが示されましたが、LLMとMLLMが直面する一般的な課題も明らかになり、これらのモデルの常識推論能力をさらに向上させる必要があることを強調しています。データと結果は以下で公開されています:
大規模言語モデルにおける常識推論の評価
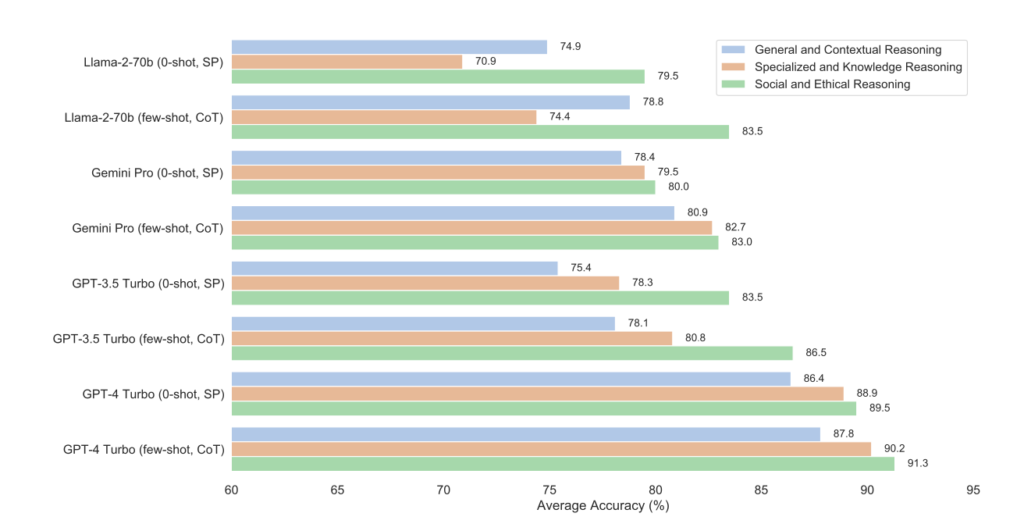
人間の常識推論能力は日常生活で欠かせないものですが、これをAIに反映させるのは困難です。最近、AIの分野では大規模言語モデル(LLM)とマルチモーダル大規模言語モデル(MLLM)が注目されており、これらはOpenAIのGPT-4VやGoogleのGeminiなどで具現化されています。特にGeminiはマルチモーダル統合に特化していますが、初期評価では常識推論の分野でのパフォーマンスに疑問が投げかけられています。本研究では、Geminiの実際の常識推論能力を広範なデータセットを用いて詳細に評価しました。結果として、Geminiは言語のみのタスクではGPT-3.5 Turboと同等のパフォーマンスを示しましたが、GPT-4 Turboと比較してやや遅れており、特に時間や社会的な推論、画像における感情認識の分野で課題が見られました。この研究はLLMとMLLMにおける常識推論の強化に向けた貴重な基盤を築いています。
マルチモーダル大規模言語モデルにおける常識推論の概観
常識推論は、基本的でしばしば暗黙の知識や信念を通じて世界を直感的に理解・解釈する、人間の知能の根幹です。マルチモーダル大規模言語モデル(MLLM)では、この能力がモデルに人間らしい言語理解と視覚的手がかりの解釈を可能にさせます。本研究では、以下のような様々な常識推論タスクを探求します:
| 領域 | 説明 |
|---|---|
| 一般常識 | 日常世界の基本的な知識への理解。 |
| 文脈常識 | 特定の文脈内での情報の解釈。 |
| 演繹常識 | 観察から最ももっともらしい説明を形成する能力。 |
| イベント常識 | イベントシーケンスと因果関係の理解。 |
| 時間常識 | 時間に関連する概念の理解。 |
| 数値常識 | 日常的な文脈での数値の理解。 |
| 物理常識 | 物理世界の理解。 |
| 科学常識 | 日常生活における科学原理の適用。 |
| 謎解き常識 | 謎かけを通じた創造的な思考の挑戦。 |
| 社会常識 | 社会的相互作用の理解。 |
| 道徳常識 | 道徳や倫理基準に基づく行動の評価。 |
| 視覚常識 | 物理的・社会的世界の文脈における視覚情報の解釈と理解。 |
これらの各領域は、MLLMが人間らしい複雑なタスクを実行するために不可欠な要素を示しています。常識推論は、これらのモデルがより洗練され、多様なシナリオで人間と効果的にやり取りするための鍵となります。
大規模言語モデルにおける常識推論の評価実験設定
常識推論を評価するため、12の異なるタイプのデータセットで実験を行いました。これには言語ベースのデータセット11種類とマルチモーダルデータセット1種類が含まれます。言語ベースのデータセットは一般・文脈推論、専門・知識推論、社会・倫理推論の3つのカテゴリに分かれています。評価には4種類の大規模言語モデル(LLM)を使用し、言語ベースのデータセットでは、標準ゼロショットプロンプティング(SP)と少数ショットの連鎖思考(CoT)プロンプティングの2つの設定を利用しています。マルチモーダルデータセットには、モデルの実際の視覚的な常識推論能力を評価するためにゼロショット標準プロンプティングを使用しています。この実験設定は、モデルが言語や視覚情報をどの程度理解し、常識推論を行えるかを評価するために設計されています。
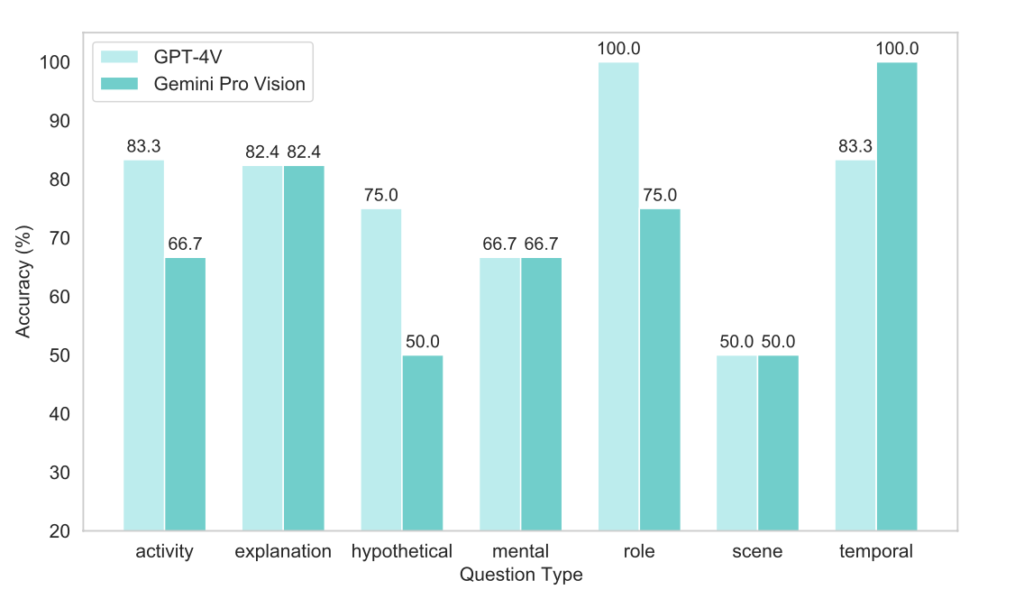
NLPにおける常識推論とLLMの評価
NLP分野では、大規模言語モデル(LLM)の常識推論能力が注目されています。これらのモデルは、テキスト分類や時系列分析など、多岐にわたるタスクでの適用が可能ですが、常識知識の理解と推論には限界があると指摘されています。特に、Googleの最新モデルGeminiの常識推論能力の評価は、その実態を把握する上で重要な課題です。本研究では、言語ベースのタスクとマルチモーダルタスクにおけるGeminiを含むLLMの評価を実施し、常識推論タスクにおける強みと限界を明らかにしました。ゼロショット学習や少数ショット学習などの学習方法や、チェーン・オブ・ソートプロンプティングなどの技術を活用し、モデルの推論と理解能力を向上させる取り組みが進められています。Geminiを含むMLLMのさらなる改善に向けた研究の発展が期待されます。
LLMおよびMLLMにおける常識推論の現状と展望
本研究では、Gemini ProやGemini Pro Visionを含む最新のLLMとMLLMを、12種類の常識推論データセットを用いて評価しました。これらのモデルは多くの領域で顕著な進歩を示していますが、時系列のダイナミクス、謎解き、複雑な社会シナリオなど、深い文脈理解や抽象的推論を要求されるタスクにおいては限界が見られます。今後の研究では、複雑な文脈や抽象的シナリオ内での解釈と推論の能力を洗練させることが重要です。さらに、AIシステムにおける常識推論のニュアンスを正確に評価するための、より包括的な評価指標と方法論が求められています。これらの指標は、回答の正確性だけでなく、その論理的整合性や文脈関連性も評価するべきです。総じて、LLMとMLLMにおける常識推論の完璧な実現は、引き続き進行中の取り組みであり、今回の成果は将来の研究の基盤を築くものです。
